About
My name is Stefan Kasberger and I love developing applications for the common good.
In my professional life, I am a Data Scientist and DevOps Engineer. I build data pipelines and am keen on automatisation, standardization and quality assurance in software development. My approach is built upon using and creating open knowledge, such as open source and open data, to create innovative software eco-systems.
Besides that, I love to hang out with my family (Hannah, Moritz and Luise) and friends, do sports or play games. So it never gets boring. :)



Portfolio
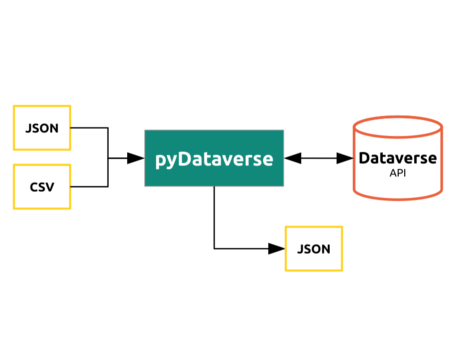
I developed an Open Source Python module for the Dataverse community. It helps to access the Dataverse API's and use its data-types.

At the University of Vienna I operated the AUSSDA Dataverse. This included all related processes, such as OAIS alignment, the CoreTrustSeal certification and the technical strategy.
Services
Developing
I use Python to create web-applications, installable packages, web-scrapers or scientific scripts. My focus is on Open Source and Open Standards, with emphasis on sustainable software development practices, such as testing, documenting and linting.
Tools
Python (Flask, FastApi, Pytest, Sphinx), Git, VSC, JavaScript, HTML, CSS
Paradigms
Open Source, OOP, Test Driven Development, Git Flow, RESTful APIs, OpenAPI
Operating
Modern web-applications are built not only with software infrastructure supporting, but also with processes surrounding it. I operate and design CI/CD pipelines & processes around applications such as Dataverse with an agile approach..
Processes
CI/CD, Monitoring, Web-Analytics, Preservation, Strategy Management
Tools
Docker, Dataverse, postgreSQL, AWS, Web-Server, Jenkins, Matomo, Selenium, Shell, Linux
Paradigms
CoreTrustSeal, OAIS, Agile, OAI-PMH, DDI
Using
Value is often created at the end of the data pipeline, when the prepared data is finally used for its intended purpose. This can be a simple visualization, a complex analytical pipeline or a service on its own.
Scientific Methods
Machine Learning, Network Analysis, Spatial Analysis, Text Data Mining, Agent-based Modelling
Scientific Tools
Python, QGIS, GRASS GIS, R, Matlab